
XR+AI Agent
Feb 2023 - Jan 2024
When we input gestures, voice commands, time, and location data into smart devices, we are essentially informing the devices of our interaction intentions through semantics that can represent such interactions. In conversations with ChatGPT and using other AIGC software, I realized that these semantics (such as a left-hand wave gesture or the current time being 10 AM) can be provided as prompts to ChatGPT. The large language model can analyze the user's behavior and intentions based on this input information and provide appropriate recommendations, in a super efficient way never before.
Based on this concept, my team and I designed and developed this experimental project, which can intelligently perceive user needs and recommend AR content.
Contributions
Project management, product definition, UX and UI design
Design&Developing Tools
Figma, Unity3D, After Effects, Xmind
issues With Single Modality
When we interact with interfaces in XR using methods such as gestures, voice commands, or object recognition, each modality of interaction exhibits varying degrees of limitations - low accuracy, low efficiency, or insufficient capability. By combining different modalities in ways that align with user intuition, we can provide users with interaction methods that are highly efficient, highly accurate, and highly scalable.

Concept: Point + Speak
This demo implemented YOLO algorithm to analyze objects captured by the camera video stream in real-time, determining their attributes and spatial relationships. Then, augmented reality glasses will use sensors and a microphone to obtain current location, time, and user voice information. Additionally, using gesture recognition technology developed with Google Mediapipe, the position of the user's index fingertip will be determined. When the fingertip overlaps with an object and a user voice command is detected, the interaction result for that point will be triggered - such as opening a workbook or a specific database.
This form of interaction fully leverages the high precision of gesture recognition and the richness of voice recognition, allowing users to penetrate multiple layers of interfaces and interact directly with the results in a natural manner. This significantly surpasses the efficiency of touchscreen interfaces.
intelligent awareness and recommendation
When we input gestures, voice commands, time, and location data into smart devices, we are essentially informing the devices of our interaction intentions through semantics that can represent such interactions. In conversations with ChatGPT and using other AIGC software, I realized that these semantics (such as a left-hand wave gesture or the current time being 10 AM) can be provided as prompts to ChatGPT. The large language model can analyze the user's behavior and intentions based on this input information and provide appropriate recommendations.
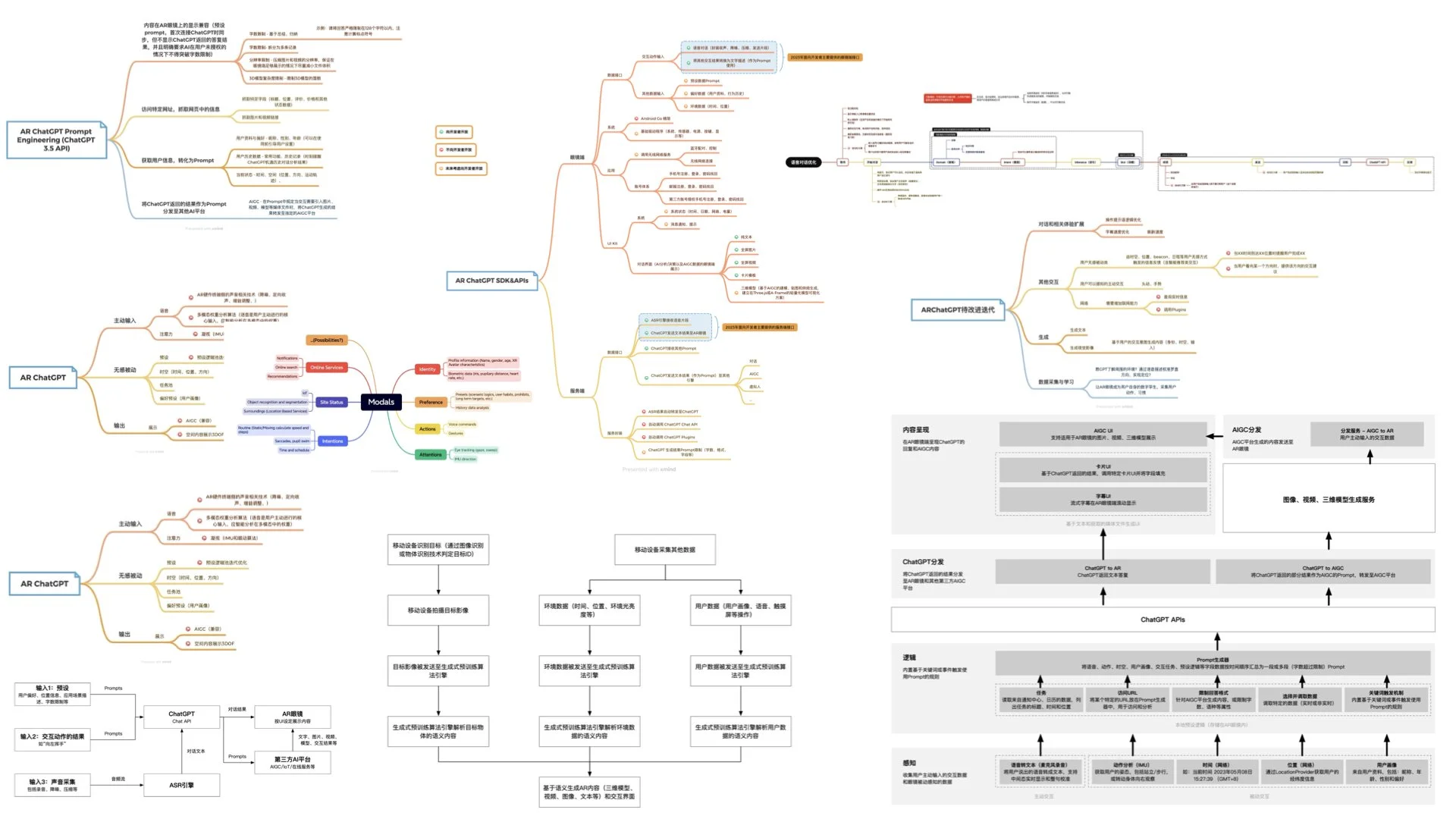
In the XR+AI demo, we designed a scenario for purchasing items in a physical store. In traditional mobile interactions, users need to complete the following steps sequentially: find the order entry, locate the product category, find the product, confirm the price, confirm the pick-up time and location, and make the payment to complete the order. If we obscure the interface elements unrelated to the ordering process, we will find that most of the information on these four main levels is useless to the user. Even the advertisements from merchants often have low conversion rates due to imprecise targeting. However, with the intelligence of large language models, this can potentially change.

In this demo, the AR glasses periodically convert the user's spatiotemporal information, visual attention model, past purchasing preferences, and store promotion information into semantics, then integrate them into a complete prompt that is continuously sent to the OpenAI ChatGPT API. When the AR glasses detect that the user is near a store, facing a counter, and their gaze meets a certain threshold, the glasses determine that the user is interested in learning about or purchasing the store's items. At this point, the product information automatically displays on the AR glasses.

Latency & accuracy Improvements
Early online large language models typically suffered from long generation times and high network latency. To prevent users from experiencing excessive wait times after submitting queries or other interaction requests, we continuously convert various current modality data into semantic form and send it to the large language model, as long as hardware power consumption permits and the user remains unaware. We generally handle 3 sessions in parallel. This way, whenever a user intervenes and triggers an interaction request, the AR glasses can provide the most relevant response based on the latest multimodal data, the user's visual attention model (primarily derived from eye-tracking gaze data), historical records, and preference presets. Compared to traditional single-threaded interactions, this approach significantly reduces latency and improves accuracy.

XR+AI =
The Next Generation XR OS
In the above prototype exploration combining large language models with XR, I have concluded the following:
Due to being closely aligned with the densely sensory-rich facial region, XR devices possess unparalleled information-gathering capabilities (such as visual attention models) and the best immediacy and immersion in information presentation. These features can be organically integrated with large language models.
In the next 3 to 5 years, the perception capabilities, computing power, and output display capabilities of XR terminals will rapidly advance, providing opportunities to create a more efficient human-computer interaction platform than smartphones.
In the more distant future, artificial intelligence will achieve self-perception, self-organization, and self-programming operating systems. At that point, the boundaries of launchers, apps, and features on XR terminals will further blur. Users may no longer need to find and open specific functions within specific applications to meet their needs. Instead, XR terminals will perceive and interpret user needs in real-time, automatically search for and download software updates, and even update their software through situational awareness of their surroundings, thereby providing users with targeted and efficient services. Its main features and graphical interface may primarily come from Artificial Intelligence Generated Content.